
In the previous post, I shared how I initialized the git repo and added some of the files you would normally have in a repo. In this post, I'll share how I set up my boilerplate for a Python project for Google Cloud/Firebase Functions, as well as unit tests, typechecks, and the other goodies needed for a good development experience.
"Boilerplates" are all the basic files needed before you write a single line of application code. Think of them like a standard "template" form which you can start building your application. While there's usually no "definitive" boilerplate for a particular task, most developers tend to build up their own from having done a few projects with a particular stack.
Here's mine for this project. The commit is here: e3f8b69 if you want to take a look. I've added files to the subfolder github_webhook_listener, I'll describe what's in here.
Application
My main code lives inside the app folder, which contains two files: an empty __init__.py, and main.py.
The __init__.py is part of the requirements for a Python package. Even though it's an empty file, it's very presence causes Python to treat this folder as a package which can be imported elsewhere. I actually only need to import this package in one place: the test suite.
The main.py file contains, currently, just a Hello World endpoint. But soon it will contain the actual webhook listener code. It looks like this currently:
""" Listens to webhooks from GitHub """
from flask import Request, escape
def hello_world(request: Request):
""" A hello world test """
request_json = request.get_json(silent=True)
name = request_json["name"]
return "Hello {}!".format(escape(name))
This function will be run by the serverless function execution runtime. The idea of serverless functions is that I just provide it with a function I want it to run, and it deals with all the config and servers and stuff. My function is provided an argument (request) that holds all the data that came in to trigger it, in this case a Flask Request object, which I can get the JSON payload from if I needed it. Soon this object will contain the webhook JSON payload that we want to decode and deal with, but for now it's just a Hello World test doing a simple thing.
Tests
Unit tests are hugely important in code. It's something a lot of new programmers skimp on, to their detriment! Tests are annoying to write and feels like it slows you down (and perhaps sometimes it does), but in a way that increases quality and avoids problems.
Unit tests benefit most for code that is very deterministic - code where given some input you can easily characterize what the output should be. APIs fall under this category, since the behaviour of APIs tend to be very deterministic - every request to an API causes some very well-defined set of behaviours and data to be returned; and of course you want and need your APIs to behave in a predictable way under all anticipated inputs.
Other kinds of code might benefit less from tests. Some argue that without exception, everything should have unit tests. I agree to an extent, but there's some grey area when it comes to algorithms that are highly stochastic or internally complex in nature. How do you unit test a neural network, for example? If you could already predict the output of a neural network given any input, then you didn't actually need the neural network. So in my mind the jury remains out on how much you should unit test certain types of code.
In this case however, we have an API, and unambiguously, this code should have tests. The tests folder contains the test suite, and the pytest.ini file contains some configurations for it. I am using Pytest, which has a few different ways of storing your tests, I've opted for this folder, which contains its own __init__.py, as well as the conftest.py, and test_main.py.
The conftest.py file is Pytest's configuration file, and it will run this file first and make its fixtures available for the other tests. Inside here, I have a simple fixture called source which returns the FUNCTION_SOURCE environmental variable. This env var contains the location of the function (app/main.py) which is needed later. It also contains a simple function for returning a random string, which is often handy for tests.
import os
import string
import random
import pytest
@pytest.fixture(scope="package")
def source():
""" Source of the functions, used for loading functions """
return os.environ["FUNCTION_SOURCE"]
@pytest.fixture
def random_id():
""" Create a random ID for various purposes """
return "".join([random.choice(string.ascii_letters) for _ in range(10)])
The test_main.py contains texts for the app/main.py file. It's pretty basic, it just tests that our Hello World function returns what we expect it to return. This test file should, if we were serious about hosting the Hello World function, test all the edge-cases, and bad inputs. For example, not providing the expected payload, or the expected payload being the wrong type, etc. However, I'm about to replace this function, so there's no need to go overboard and write a complete test suite for the Hello World function!
from functions_framework import create_app # type: ignore
def test_hello_world(source, random_id):
client = create_app("hello_world", source).test_client()
res = client.post("/", json=dict(name=random_id))
assert res.status_code == 200
assert res.get_data(as_text=True) == f"Hello {random_id}!"
The local test here uses functions-framework a framework for easily testing Google Cloud Functions locally.
Coverage
Test coverage is also important. Test coverage tells you how much of your code was covered/executed, when you ran the test suite. It's a tool that tells you what code isn't adequately tested because that code was never executed during testing. I use pytest-cov; and to help, I've added a .coveragerc to contain any specific configuration needed for it (such as telling it which folders contain code to be tested).
This is what it looks like when I run a test on this boilerplate:
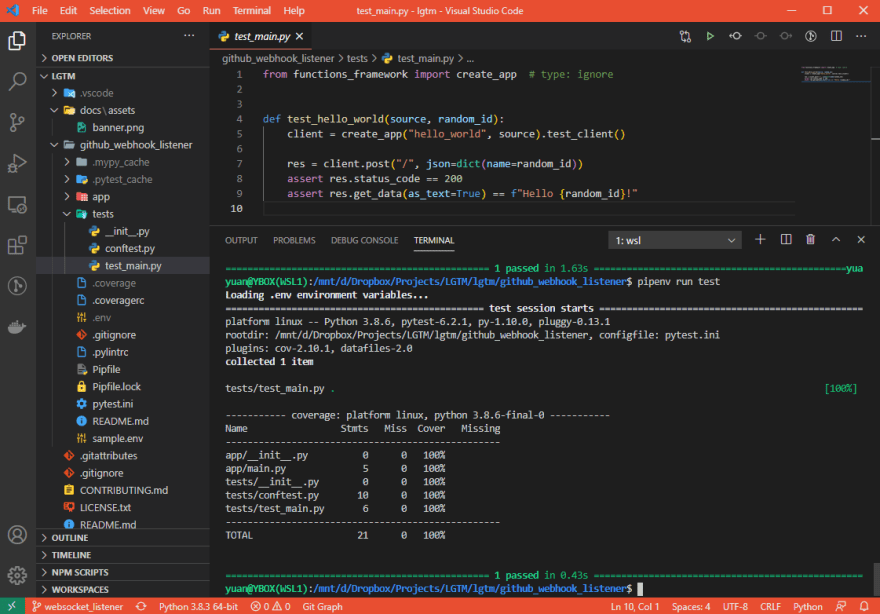
I have 100% test coverage! However, two things to note: I also include the tests themselves in the coverage, so I can make sure ALL of the tests were being executed (there are some mistakes you can make where tests were skipped, so this coverage stat is useful as a way of making sure you didn't make those mistakes). And secondly, 100% test coverage doesn't mean all my tests were good and covered all the possible edge-cases that should be tested. For example, as discussed above, I know we didn't write tests for cases where the Hello World payload was malformatted.
Had I had less than 100% test coverage, this output would also have told me exactly what lines were not covered, letting me investigate them. There's also an HTML formatted version that gives me a view of the code, highlighted according to their test coverage; and various editor extensions can also display the results.
Environmental variables
Environmental variables are variables provided to the script by the environment it's running in. Sometimes it's used for configuration purposes, other times for getting information about the host to the script.
The functions-framework library that I'm using needs to be told where the target function lives, and expects a FUNCTION_SOURCE environmental variable to be provided. I provide this using a feature of pipenv (described later), and a .env file, which has been gitignored. I normally gitignore .env files because they may contain secrets like access keys needed by the app, and shouldn't be shared in the source code of this open source project. Instead, I provide a sample.env file which lets other developers know that these are the env files they will need to set, they can copy sample.env to .env and edit as needed.
Gitignore
As described previously, .gitignore files contain a list of files that should not be checked into the repo. I'm using a standard Python .gitignore file, which includes a bunch of stuff known to be generated by python project, which aren't needed. Things like the .pytest_cache folder that is generated by Pytest, or the .coverage file containing coverage results. It also contains the .env file by default
Pylint
"Linting" is the act of automatically checking code for bugs and style errors, it uses static analysis to check for issues, which means it doesn't need to run the code to do it. It's often built-into (or configured to be used by) programmer's text editors so that code is linted as they program, allowing bugs and errors to be caught early before even running the code. It makes development a lot easier because it's easy to make syntax errors, and annoying to find out after running the code, and then fixing it, and then discovering another one the next ron, etc. etc.
Linting also covers style issues. It helps you program in a consistent way, which makes your code more readable to others. So for that reason, it's a very good tool for learners to use.
I use Pylint to do this, and so I include a .pylintrc file that contains all the linter settings for a style that I like. My main changes to the linter is to re-enable the linter warnings for print() functions, since these aren't useful for cloud functions (one should use the logger instead); disable the duplicate-code output; and define variables like fp to be valid stylistically.
Another kind of static test involves checking types. Python now has type hinting, which means you can annotate your variables and function arguments with the expected types of variables. This too prevents a lot of different kinds of errors that you can catch before running the code. There are often hard-to-find edge-cases caused by incorrect types (particularly nulls/Nones), so having this kind of static check is important. In our repo, this is done by the tool mypy but there isn't any specific file relating to it in the structure.
Pipfile
Environment management is very important. Different codebases require different packages, and sometimes these packages will have conflicting versions of dependencies, which means you'll have to go uninstall a package needed by one project, to install a different version of it for another. So, python projects keep their dependencies separated per-project using virtual environments. Each project then has its own environment, into which its own, isolated, set of package dependencies can be installed.
I use Pipenv for this. It combines this virtual environment stuff with a couple other features: a lockfile, which contains a list of every dependency version that was installed. This lockfile is important for reproducibility - it means someone else using this project can install the exact versions of packages that I had on my machine, and avoid the issue of "well it worked on my machine". The lockfile is a lot like requirements.txt, but has hashes for integrity, and also works as a pair with the Pipfile: while the Pipfile contains a high-level list of the packages you chose to install, the Pipfile.lock that gets generated contains all of those packages and every dependency that was installed as a result. Another developer can then opt to install exactly the versions from before, or update everything using new versions.
Readme
Finally, the all-important README.md file. Unlike the one in the root directory, this one contains more information about this github_webhook_listener including some information for other developers about what is needed to get this code set up and running on their machines for development/testing.
I hope that's a useful overview for anyone looking to get started with their own Python projects, in particularly a Google Cloud Functions in Python project, which is what this is a boilerplate for.





Top comments (0)