

In this article, you will learn how to monitor kube-proxy to ensure the correct health of your cluster network. Kube-proxy is one of the main components of the Kubernetes control plane, the brains of your cluster.
One of the advantages of Kubernetes is that you don’t worry about your networking or how pods physically interconnect with one another. Kube-proxy is the component that does this work.
Keep reading to learn how you can collect the most important metrics from kube-proxy and use them to monitor this service.
What is kube-proxy?
Kube-proxy is an implementation of a network proxy and a load balance that serves as the link of each node with the api-server. It runs in each node of your cluster and allows you to connect to pods from inside or outside of the cluster.
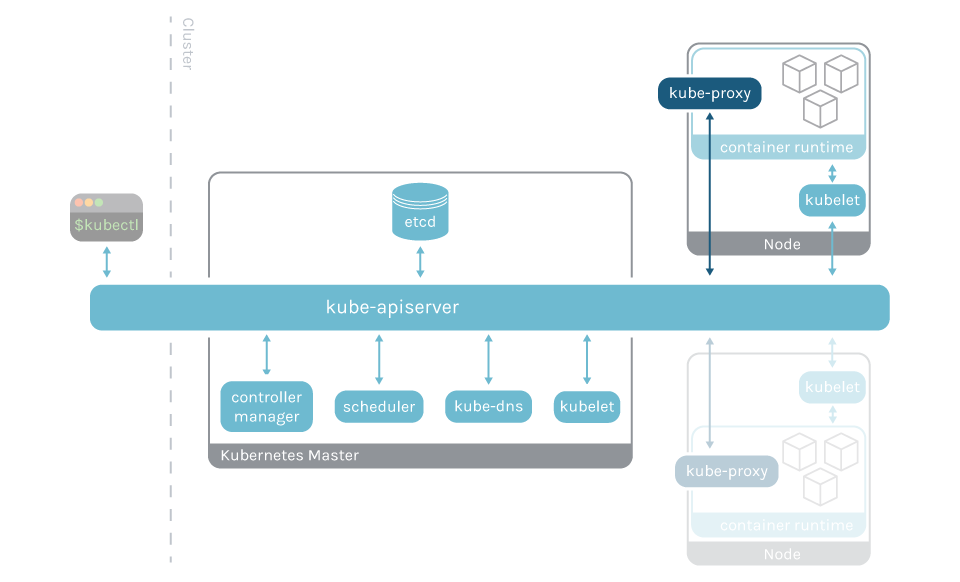
How to monitor kube-proxy
You’ll have to monitor kube-proxy, under the kube-system namespace, on all of the cluster nodes except the master one.
Getting metrics from kube-proxy
Like the rest of Kubernetes control plane parts, the kube-proxy is instrumented with Prometheus metrics, exposed by default in the port 10249. This metrics endpoint can be easily scraped, obtaining useful information without the need for additional scripts or exporters.
As the metrics are open, you can just scrape each kube-proxy pod with curl:
curl https://[kube_proxy_ip]:10249/metrics
It will return a long list of metrics with this structure (truncated):
...
# HELP rest_client_request_duration_seconds Request latency in seconds. Broken down by verb and URL.
# TYPE rest_client_request_duration_seconds histogram
rest_client_request_duration_seconds_bucket{url="/https://XXXX%7Bprefix%7D",verb="GET",le="0.001"} 41
rest_client_request_duration_seconds_bucket{url="https://XXXX/%7Bprefix%7D",verb="GET",le="0.002"} 88
rest_client_request_duration_seconds_bucket{url="https://XXXX/%7Bprefix%7D",verb="GET",le="0.004"} 89
rest_client_request_duration_seconds_count{url="https://XXXX/%7Bprefix%7D",verb="POST"} 7
# HELP rest_client_request_latency_seconds (Deprecated) Request latency in seconds. Broken down by verb and URL.
# TYPE rest_client_request_latency_seconds histogram
rest_client_request_latency_seconds_bucket{url="https://XXXX/%7Bprefix%7D",verb="GET",le="0.001"} 41
...
rest_client_request_latency_seconds_sum{url="https://XXXX/%7Bprefix%7D",verb="POST"} 0.0122645
rest_client_request_latency_seconds_count{url="https://XXXX/%7Bprefix%7D",verb="POST"} 7
# HELP rest_client_requests_total Number of HTTP requests, partitioned by status code, method, and host.
# TYPE rest_client_requests_total counter
rest_client_requests_total{code="200",host="XXXX",method="GET"} 26495
rest_client_requests_total{code="201",host="XXXX",method="POST"} 1
rest_client_requests_total{code="<error>",host="XXXX",method="GET"} 91
...
If you want to configure a Prometheus server to scrape kube-proxy, just add the next job to your scrape configuration:
- job_name: kube-proxy honor_labels: true kubernetes_sd_configs: - role: pod relabel_configs: - action: keep source_labels: - __meta_kubernetes_namespace - __meta_kubernetes_pod_name separator: '/' regex: 'kube-system/kube-proxy.+' - source_labels: - __address__ action: replace target_label: __address__ regex: (.+?)(\\:\\d+)? replacement: $1:10249
Remember to customize it with your own labels and relabeling configuration as needed.
Monitor kube-proxy: What to look for?
You should use Golden Signals to monitor kube-proxy; Golden Signals is a technique to monitor a service through the metrics that give the right insights on how it’s performing for the customer. These metrics are latency, requests, errors, and saturation.
Disclaimer: kube-proxy metrics might differ between Kubernetes versions. Here, we used Kubernetes 1.18. You can check the metrics available for your version in the Kubernetes repo (link for the 1.18.3 version).
Kube proxy nodes are up: The principal metric to check is if kube-proxy is running in each of the working nodes. Since Kube-proxy runs as a daemonset, you have to ensure that the sum of up metrics is equal to the number of working nodes.
An example alert to check Kube-proxy pods are up would be:
sum(up{job=\"kube-proxy\"}) < number of working nodes
Rest client latency: It’s a good idea to check the latency for the client request; this information can be found in the metric rest_client_request_duration_seconds_bucket:
# HELP rest_client_request_duration_seconds Request latency in seconds. Broken down by verb and URL.
# TYPE rest_client_request_duration_seconds histogram
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.001"} 41
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.002"} 88
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.004"} 89
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.008"} 91
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.016"} 93
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.032"} 93
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.064"} 93
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.128"} 93
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.256"} 93
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="0.512"} 93
rest_client_request_duration_seconds_bucket{url="https://URL/%7Bprefix%7D",verb="GET",le="+Inf"} 93
rest_client_request_duration_seconds_sum{url="https://URL/%7Bprefix%7D",verb="GET"} 0.11051893900000001
rest_client_request_duration_seconds_count{url="https://URL/%7Bprefix%7D",verb="GET"} 93
This alert will warn you if there are more than 60 slow POST requests in your cluster network in the last five minutes:
histogram_quantile(0.99, sum(rate(rest_client_request_duration_seconds_bucket{job="kube-proxy",verb="POST"}[5m])) by (verb, url, le)) > 60
Rule sync latency: The kube-proxy is synchronizing its network rules constantly between nodes. It’s a good idea to check how long this process takes, because if it increases, it can cause the nodes to be out of sync.
# HELP kubeproxy_sync_proxy_rules_duration_seconds SyncProxyRules latency in seconds
# TYPE kubeproxy_sync_proxy_rules_duration_seconds histogram
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.001"} 2
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.002"} 2
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.004"} 2
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.008"} 2
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.016"} 2
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.032"} 75707
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.064"} 199584
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.128"} 209426
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.256"} 210353
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="0.512"} 210411
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="1.024"} 210429
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="2.048"} 210535
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="4.096"} 210550
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="8.192"} 210562
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="16.384"} 210565
kubeproxy_sync_proxy_rules_duration_seconds_bucket{le="+Inf"} 210567
kubeproxy_sync_proxy_rules_duration_seconds_sum 8399.833554354082
kubeproxy_sync_proxy_rules_duration_seconds_count 210567
Code of the requests: You should monitor the HTTP response codes of all the HTTP requests in the cluster. Something wrong is happening if the number of requests with errors rise.
# HELP rest_client_requests_total Number of HTTP requests, partitioned by status code, method, and host.
# TYPE rest_client_requests_total counter
rest_client_requests_total{code="200",host="host_url",method="GET"} 26495
rest_client_requests_total{code="201",host="host_url",method="POST"} 1
rest_client_requests_total{code="<error>",host="host_url",method="GET"} 91
rest_client_requests_total{code="<error>",host="host_url",method="POST"} 6
For example, to warn on a rising number of requests with code 5xx, you could create the following alert:
sum(rate(rest_client_requests_total{job="kube-proxy",code=~"5.."}[5m])) by (host,method)/sum(rate(rest_client_requests_total{job="kube-proxy"}[5m])) by (host,method) > 0.10
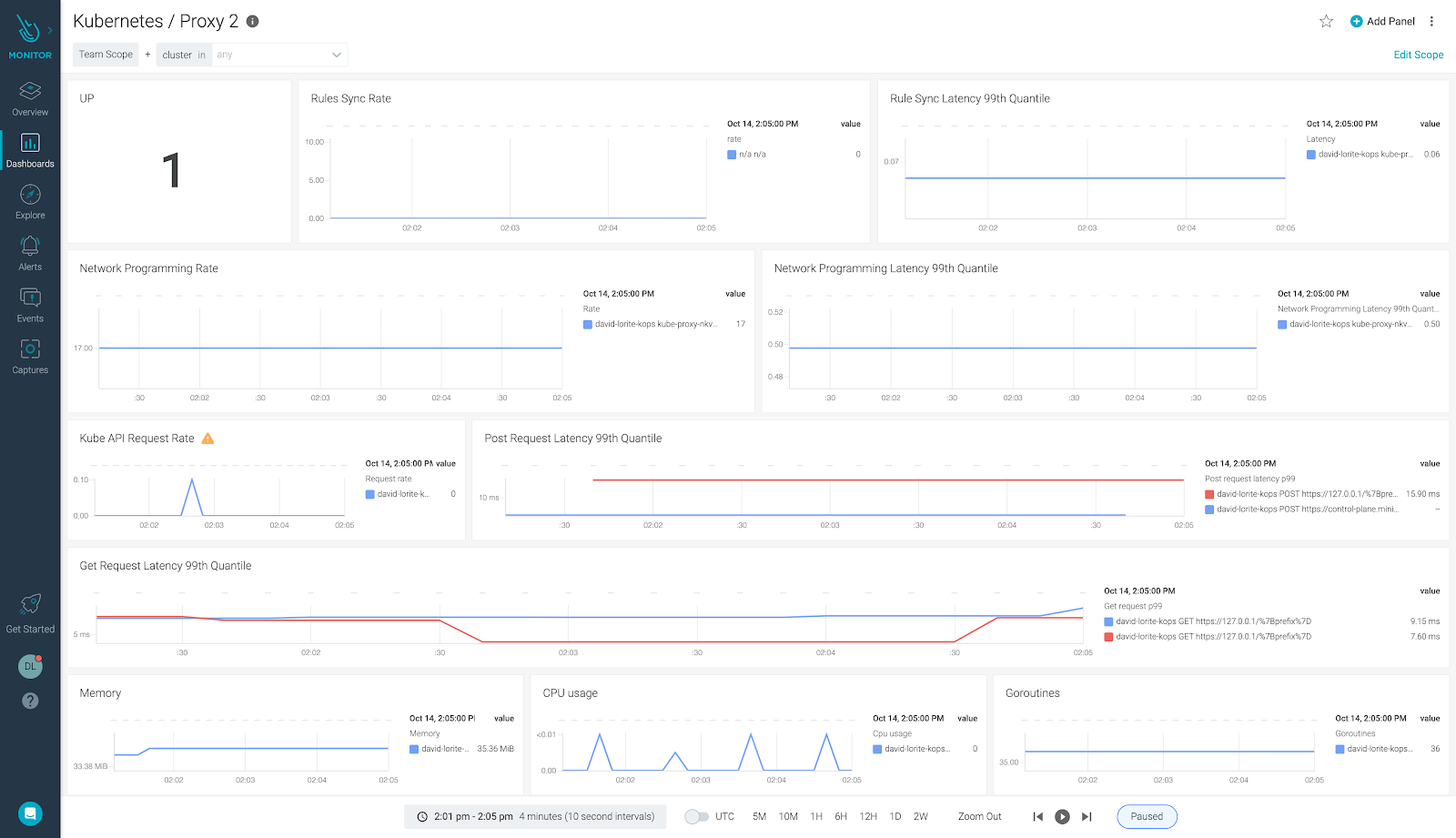
Monitor kube-proxy metrics in Sysdig Monitor
In order to track kube-proxy in Sysdig Monitor, you have to add some sections to the Sysdig agent YAML configuration file, and use a Prometheus server to filter the metrics.
You can choose not to use an intermediate Prometheus server, but you have to keep in mind that kube-proxy provides a lot of metrics. You only need a few of them, so this strategy simplifies things a lot.
First of all, you need a Prometheus server up and running.
If you don’t have it, then don’t worry. Deploying a new Prometheus is as simple as executing two commands. The first is to create a namespace for the Prometheus, and the second is to deploy it with helm 3.
kubectl create ns monitoring helm install -f values.yaml prometheus -n monitoring stable/prometheus
Being the contents of the values.yaml file as follows:
server: strategy: type: Recreate podAnnotations: prometheus.io/scrape: "true" prometheus.io/port: "9090"
Once Prometheus is up and running, you have to create filtering rules to select the metrics you want. These rules create new metrics with a custom label that is then used by the Sysdig agent to know which metrics should be collected.
You can find the rules on PromCat.io. You can also find all of the steps needed to monitor kube-proxy in Sysdig.
This is an example agent configmap:
apiVersion: v1
kind: ConfigMap
metadata:
name: sysdig-agent
namespace: sysdig-agent
data:
prometheus.yaml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus' # config for federation
honor_labels: true
metrics_path: '/federate'
metric_relabel_configs:
- regex: 'kubernetes_pod_name'
action: labeldrop
params:
'match[]':
- '{sysdig="true"}'
sysdig_sd_configs:
- tags:
namespace: monitoring
deployment: prometheus-server
Conclusion
The kube-proxy is usually a forgotten part of your cluster, but a problem in kube-proxy can bring down your cluster network. You should know when something weird is happening and be alerted about it.
Monitoring kube-proxy with Sysdig Monitor is easy. With just one tool you can monitor both kube-proxy and Kubernetes. Sysdig Monitor agent will collect all of the kube-proxy metrics, and you can quickly set up the most important kube-proxy alerts.
If you haven’t tried Sysdig Monitor yet, you are just one click away from our free trial!